

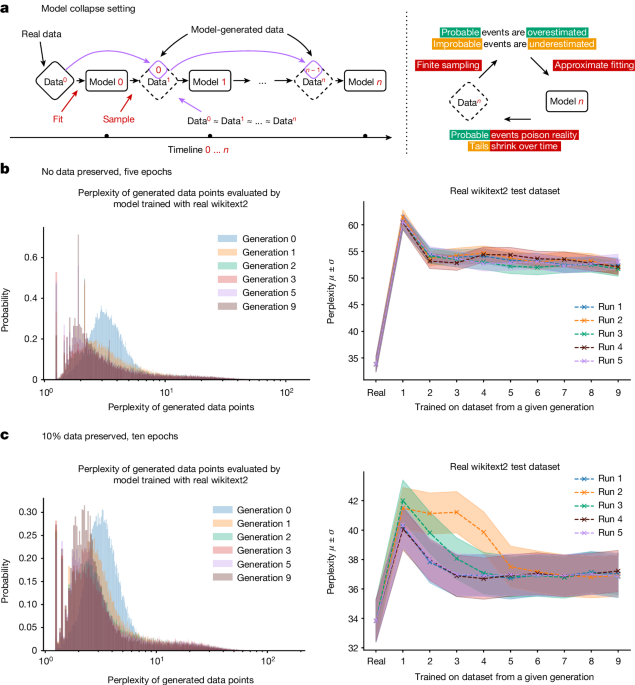
It is now clear that generative artificial intelligence (AI) such as large language models (LLMs) is here to stay and will substantially change the ecosystem of online text and images. Here we consider what may happen to GPT-{n} once LLMs contribute much of the text found online. We find that indiscriminate use of model-generated content in training causes irreversible defects in the resulting models, in which tails of the original content distribution disappear. We refer to this effect as ‘model collapse’ and show that it can occur in LLMs as well as in variational autoencoders (VAEs) and Gaussian mixture models (GMMs). We build theoretical intuition behind the phenomenon and portray its ubiquity among all learned generative models. We demonstrate that it must be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of LLM-generated content in data crawled from the Internet.
Good. Those models flooded the internet with shit, so they can eat it.
“Don’t shit where you eat” is solid advice no matter the venue.
Haha, well said
Repeating lossy compression on a dataset produces lossier data, which seems pretty intuitive, glad it is spelled out in a paper.
Moar jpg?
Deep-fried LLMs.
Large Lunch Models
So one potentially viable way to destroy AI would be to repeatedly train LLMs and image generators on their own (or rather previous generations’) output to get garbage/junk/bad training data and then publish the text/images in places where bots trawling for training data are likely to find them.
Probably bonus points if the images still look “sensical” to the human eye, so that humans eyeballing the data don’t realize it’s the digital equivalent of a sabot. (Apparently the story about sabots being thrown into machinery is not true, but you know what I mean.)
I already block all the LLM scraper bots via user agent.
I’ve been toying with the idea of, instead of returning 404 for those requests, returning LLM-generated drivel to poison the well.
This is a really good idea actually
train LLMs and image generators on their own (or rather previous generations’)
AIncest!
Deep fried AI.
Honestly, that’s pretty much what I expected. It’s just an incestuous mash up of pre-existing data. The only way I could see it working is by expanding specific key terms to help an AI identify what something is or isn’t. For example, I have a local instance generate Van Gogh paintings that he never made because I love his style. Unfortunately, there’s a bunch of quirks that go along with that. For instance: Lots of pictures of bearded men, flowers, and photos of paintings. Selecting specific images to train the model on “Van Gogh” might make sense because of the quality of the initial training data. Doing it recursively and automatically? That’s bad mojo.
Yes this isn’t news- it’s called AI cannibalism and it’s the high tech version of making a tape of a tape of a tape. It’s part of the great enshitification.
Consider this: a lot of general knowledge is trained into ai using Wikipedia. Since ai bots have a friendly chat interface and natural language processing that makes a decent attempt at understanding context and language intent, asking ChatGPT to look something up results in an interestingly summarized, cross referenced answer that might draw from 5 or 6 wiki articles that otherwise might have required a couple hours of reading and diving to derive organically (with your meat computer). Since just asking ChatGPT is way easier than spending 2 hours clicking on Wikipedia, people start just using the bot instead of Wikipedia. Fast forward 5-10 years. People don’t even go to wiki anymore because why would you? People stop contributing to wiki because no one goes there anyway, it’s as useless as a serial port gender changer. So now 90% of the web is just the summarized output of ai bots. Wiki goes offline because no one donates, no one visits. Now the latest gen AI is trained on Russian troll bots, Instagram comment sections, and Reddit comments which have all become 90% ai bot spam. The thing that made AI good was the quality of the training data but now all the new data is absolute trash, just SEO ad garbage. The generation of AI model trained on that can’t help but produce total static because who the fuck is taking the effort the put real quality on the net anymore?
I’m really sad about this future… (this present).
Sadly, there’s a silver lining for giga corporations exclusively. They have near endless resources to amass more and more human made data and IPs to keep feeding their content machine for years to come. You and me won’t be able to train anything decent from datasets that scrape random websites anymore for the known reasons, but Microsoft, Facebook and Google are above us filthy plebs in that they already own or are able to pay for high quality datasets that they can monetize completely legally. I mean they’re lobbying for exactly that: To lock the tech away from the public. And of course the US government being the US government, they make it happen already with nightmarish regulations that hand the keys to the tech to the super rich.
Though I wonder how much enshittification us people can take before we simply leave most parts of the internet to experience real life instead. Because the digital world looks more surreal by the day lately and it kind of stops existing as soon as we avert our eyes from our screens.
Apparently this is a major problem with both AI models and circular human centipedes.
This will drive billions into refining the surveillance state. They now know they need genuine original human interaction and will do everything possible to capture everything from texts to cctv footage
So, should we update the Glaze toolset or should we all just host pages and pages of AI generated images? Maybe someone can write something that allows iframes/blocks that just load sheets of midjourney images and reloads nightly. Maybe add some text that is written in prompt style commands just to really fuck with these. Anyway, obligatory “we have the tools”
While it’s good to be precautious about future scenarios, it’s hard to believe AI won’t help greatly with innovation. The AI will become more biased, ok. But what about all the prompts people make? If there is a solid fact basis in the AI model, why bother? Especially when the output works.
That’s what this is about… Continual training of new models is becoming difficult because there’s so much generated content flooding data sets. They don’t become biased or overly refined, they stop producing output that resembles human text.





